Python 기초 탄탄 세션

● 가장 많이 사용하는 자료형은 String, List, Dictionary 자료형이다.
○ 각각 자료형은 특정한 문법으로 표기한다.
■ 리스트 : 대괄호 [ 11, '안녕하세요' ]
■ String : 따옴표 ' '. " " '안녕하세요. 저는"보미"입니다.'
■ Dictionary : 중괄호와 콜론 { : }
1. 문자열 ( str, string )
● ' ' , " " 로 정의함
● 따옴표는 문자열의 시작과 끝을 표시하고, 문자열 데이터에 포함되지 않는다. print( 'a' ) → a
● my_str = '가나다' 와 같이 정의하면 my_str 변수명에 리스트 형태가 저장되며, type(my_str)라고 출력하면 str라고 하는 자료형임을 알려준다.

▶ 인덱싱 (indexing) 과 슬라이싱 (slicing)

● index : 자료형을 구성하는 순번. my_str[0]
● 첫번째 인덱스값은 0이며, 마지막 인덱스값은 -1이다.
● 인덱스 슬라이싱을 이용해 필요한 자료를 추출할 수 있다.

▶ 문자열과 내장함수

2. 리스트 (List)
● list() , [ ] 를 이용해 정의할 수있음

3. 딕셔너리 ( Dictionary )
● key - value 형태로 정의됨
○ key : 딕셔너리의 인덱스와 같은 개념, 인덱스로 불러오기 되며 특정 key값으로 값을 접근해야함
○ value : 말 그대로 key와 엮어있는 값

4. 퀴즈
1) set 이므로 중복은 제거 (1, 2)

2)

3)

심화)

1. 조건문
- 퀴즈 -

- 퀴즈 -
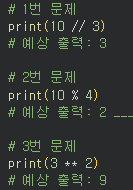
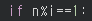
- 퀴즈 - : 2로 나누었을 때 나머지가 0이면 짝수이다.
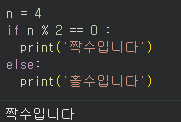
- 조건문 문제 -

2. for 문
● 문법


- 퀴즈 -



3. 기타 구문 : pass, continue, break
● pass : 일단 함수 이름만 만들어 놓음. 예를 들면 짝수를 판별하는 함수를 만들어놓고 다른 작업을 먼저 하고 싶을 때 사용함. (코드가 비어있음, 다른 작업을 먼저 할 수 있음)
● continue : 아래 코드를 무시하고 즉시 다음 루프를 실행 (건너뛰기)

● break : 현재 돌고 있는 루프를 깨고나와서 종료 (깨짐)

● 문제 1
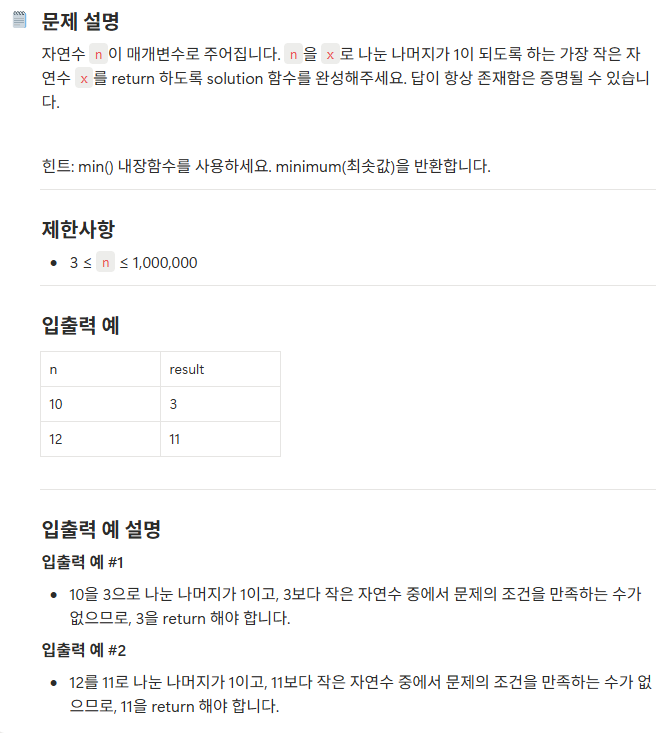

- solution 함수를 정의
- n 값을 입력받음

- 1부터 n-1 까지 반복
- n 을 i 로 나눈 나머지가 1이면

- 조건에 만족한 i 를 리스트에 추가

- 조건을 만족하는 값들 중 가장 작은 수 [min()] 를 반환

📋전체 코드

● 문제 2


- HACCP 검사를 받지 않은 품목 찾기

- 빈 리스트 생성 (미검사 품목 저장)

- 딕셔너리의 key만 가져옴

- 검사 여부 확인 ( Sausage_C not in haccp_tested → True )

- 미검사 리스트에 추가 ( untested_products = [ " Sausage_C" ] )

- 최종 리스트 결과 반환

- 미 검사 품목 중에서 중량이 100g 미만인 품목 찾기

- 미검사 품목 가져오기

- 중량 미달 저장 리스트 생성

- 반복문(중량 확인) 실행 ( product = Sausage_C )

- 중량 확인 = 딕셔너리 값 가져오기 ( factory_products [Sausage_E] < 100)

- 리스트에 추가(append)하기 ( [Sausage_E] )

- 개수 세기( ["Sausage_E, Sausage_F"] )
📋전체 코드

📋아티클 스터디
주제 : 데이터 시각화는 왜 중요할까?
https://yozm.wishket.com/magazine/detail/1750/
데이터 시각화 101: 1 데이터 시각화는 왜 중요할까? | 요즘IT
데이터의 양이 늘어나고 복잡해질 수록 데이터를 좀 더 쉽게 이해하고 인사이트를 발견하는 것의 필요성이 높아지고 있는데요. 데이터 시각화란 말 그대로 데이터에서 발견한 정보를 시각적으
yozm.wishket.com
● 요약 : 시각이 가장 많은 양의 정보를 빠르게 처리한다는 점에서, 데이터 시각화가 정보 이해도를 높이고 직관적인 인사이트를 제공하며 복잡한 문제를 쉽게 설득하여 올바른 의사결정을 내리도록 돕는 결정적 역할을 한다.
● 주요 포인트
- 인간의 뇌는 텍스트보다 그래픽 정보를 약 6만배 더 빠르게 처리한다.
- 텍스트나 표형태로는 보이지 않던 데이터의 트렌드, 규칙성, 특이점을 시각화를 통해 단번에 파악할 수 있다.
- 복잡한 통계 지식이 없어도 누구나 직관적으로 데이터를 이해할 수 있게 만든다.
● 핵심 개념
- 시각 매핑 : 원본 데이터가 가진 수치나 정보를 색상, 길이, 위치 등 사람이 직관적으로 인지할 수 있는 그래픽 요소로 변환하여 대응시키는 과정이다.
- 아하! 모먼트 : 방대한 데이터 속에서 시각화된 결과물을 보고 트렌드나 패턴, 인사이트를 직관적으로 깨닫게 되는 순간이다.
● 용어 정리
- 데이터 시각화 : 데이터에서 발견한 정보와 인사이트를 사람들이 쉽게 이해할 수 있도록 차트, 지도, 그래프 등 그래픽 형태로 표현하는 것
- 아웃라이어 : 데이터 전체의 일반적인 패턴에서 크게 벗어나 극단적으로 크거나 작은 값을 가진 데이터 포인트
- 시뮬레이션 : 가상의 환경이나 모델을 구축하여 실제 현상이 어떻게 전개될지 예측하고 실험하는 기법
● 실무 적용 사례
- 실무 적용 : 공간 전사체학 및 분자 구조 시각화
→ 공간 전사체학 : 손상되지 않은 조직 내에서 전사활동의 위치적 맥락을 영역 또는 single cell에 대해 포착하는 능력
- 관련 사례 : 연구원들은 암 조직의 유전자 발현 데이터를 실제 조직 이미지 위에 색상과 위치로 매핑한다. 이를 통해 암 세포 주변에 어떤 면역 세포들이 몰려 있는지(종양 미세환경)를 지도 보듯 시각적으로 확인한다. 특정 면역 억제 단백질이 뭉쳐있는 핫스팟을 직관적으로 발견하여, 해당 단백질을 표적으로 삼는 신약 후보 물질을 발굴할 수 있다.
🤔
이번 학습을 통해 파이썬에서는 문자열, 리스트, 딕셔너리 같은 자료형이 많이 사용되며, 데이터를 상황에 맞게 저장하고 활용하는 방법이 중요하다는 것을 배웠다. 또한 조건문과 반복문을 이용하면 원하는 조건에 맞게 데이터를 처리하고 반복 작업을 효율적으로 수행할 수 있다는 점도 이해하게 되었다.
특히 실습 문제를 직접 풀어보면서 단순히 문법을 외우는 것이 아니라, 데이터를 분석하고 필요한 값을 찾아내는 과정이 실제 문제 해결과 연결된다는 점이 흥미로웠다. 반복문과 조건문을 활용해 HACCP 검사 여부나 제품 중량 데이터를 처리해보며, 파이썬이 데이터를 체계적으로 관리하고 분석하는 데 유용한 도구라는 것을 느꼈다.
데이터 시각화는 단순히 데이터를 꾸미는 것이 아니라, 많은 정보를 한눈에 이해할 수 있게 도와주는 중요한 방법이라는 점이 인상 깊었다. 그래프나 색상 같은 시각 요소를 사용하면 표나 글로는 잘 보이지 않던 패턴이나 이상값도 쉽게 발견할 수 있다는 것을 알게 되었다.
또한 어려운 통계 지식이 없어도 데이터를 직관적으로 이해할 수 있어서, 데이터를 설명하거나 의사결정을 할 때 큰 도움이 된다는 점도 중요하다고 느꼈다. 실제 바이오 분야에서는 암 조직의 유전자 데이터를 시각화하여 면역세포의 위치나 특정 단백질이 몰린 부분을 쉽게 찾아 신약 개발에 활용하고 있다는 점이 흥미로웠다.