
오늘은 데이터 전처리&시각화 강의에서 데이터 전처리와 그래프 그리는 방법을 복습했다. 그리고 오후 3시에 있던 허진성튜터님의 라이브 세션 3회차를 듣고 잘 이해가 안됐던 부분을 VS code로 실행해보고 GPT한테 코드를 뜯어서 문제를 해결했다. 아침에 Atani랑 코드카타를 풀었는데 Atani에서 지도학습과 비지도학습부분을 잘 몰라서 많이 틀렸다. 개념을 다시 잡고 이해해야겠다.
🤖Atani

⭐
사실 찍었다. A, C, D가 다 그럴듯해보여서 B 를 골랐다.
회귀 분석은 연속형 종속변수를 예측하는 기법이다. 종속변수가 범주형일 때는 로지스틱 회귀나 분류 알고리즘을 사용함.
A : 회귀 분석의 기본 정의
C : 회귀 분석의 주요 목적
D : 독립변수 개수에 따른 분류(단순, 다중)

⭐
| 단순 선형 회귀 | 다중 회귀 |
| 독립변수가 1개인 경우 | 독립변수가 2개 이상인 경우 |
| y = ax + b | y = a1x1 + a2x2 + ...+b |
A : 잘못된 설명, 둘다 선형 관계를 가정함
C : 틀림. 둘다 오차의 정규분포를 가정함
D : 틀림. 둘다 예측에 사용됨

⭐
X의 형태가 [[값]] 형태로 독립변수가 1개만 있고, y는 연속형 값임. → 단순 선형 회귀
다중 선형 회귀라면 X가 [[x1, x2, ...]] 형태로 여러 특성을 가져야 함.
다항 회귀는 PolynomialFeatures를 사용해야 함.
로지스틱 회귀는 LogisticRegression 클래스를 사용함.

❌ 오답!!!!!!
⭐ 정답 : A
지도학습과 비지도학습의 가장 핵심적인 차이는 레이블(정답) 데이터의 유무임.
| 지도학습 | 비지도학습 |
| 입력 데이터와 그에 대응하는 정답(레이블)이 함께 주어져 학습하는 방법 | 레이블 없이 데이터의 패턴이나 구조를 찾아내는 방법 |
B : 반대로 설명되어있음
C, D : 두 학습 방법의 차이와 무관한 내용임.

❌ 오답!!!!!!
⭐ 정답 : A
A : 선형 회귀, 로지스틱 회귀, 의사결정나무는 모두 레이블이 있는 데이터로 학습하는 지도학습 알고리즘
B : 모두 군집화(클러스터링) 알고리즘으로 비지도학습에 해당
C : 차원 축소 알고리즘으로 비지도학습
D : 지도학습과 비지도학습 알고리즘이 섞여있음. (K-means와 PCA는 비지도학습)
⌨️코드카타









🤓 데이터 전처리 & 시각화 강의 복습
● iloc에서 슬라이싱을 할때
파이썬 슬라이싱에서 숫자 값인 경우에는
마지막 인덱스를 포함하지 않고 그 전까지의 값을 가져오는 형태
● 반면에 loc에서 인덱스명을 입력할 때
해당값을 포함하여 데이터를 불러오게 되는 차이점이 있음
ex) df = pd.DataFrame({
'A' : [1,2,3,4,5],
'B' : [10,20,30,40,50],
'C' : [100,200,300,400,500]
}, index = ['a', 'b' ,'c' ,'d', 'e'])
- df. iloc [ :,0]

- df. loc [ :, 'A']
● 불리언 인덱싱
여러가지 조건을 할때
- and : &
- or : |
● concat 으로 인덱스를 합칠때 0123,0123,0123 되는걸 reste_index(drop=True)를 이용해서 0123456으로 바꿀수 있음

↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓

● concat과 merge의 차이점
| concat | merge |
| 데이터 프레임을 위아래, 좌우로 병합하는 메서드 | 특정 컬럼을 고려해서 병합하는 메서드 (SQL에서 join문법과 동일한 결과값을 산출할 때 활용됨) |
● pd.merg(a,b, on = '이름', how = 'inner')
- on : 병합하고자 하는 기준이 되는 컬럼 지정
- how는 inner로 디폴트가 되어있고, outer로 변경하면 전체 데이터가 출력되는 것을 확인할 수 있음.
- left : 왼쪽에 적어놓은 a를 기준으로 a에 대한 데이터 값이 변경되지는 않으면서 그 데이터 안에 속하는 b에 해당하는 값들을 넣어주는 것
- right : left의 반대
● 데이터 정렬
- sort : 디폴트는 오름차순,
- ascending = False : 내림차순으로 변경
- 여러개의 컬럼별로 정렬하기
ex) df. sort_values (by = ['Age', 'Score'], ascending = [True, False])
Age : 오름차순, Score : 내림차순 → Age 정렬이 먼저 적용되고 다음 Score가 정렬됨.
🖥️ 라이브세션 실습




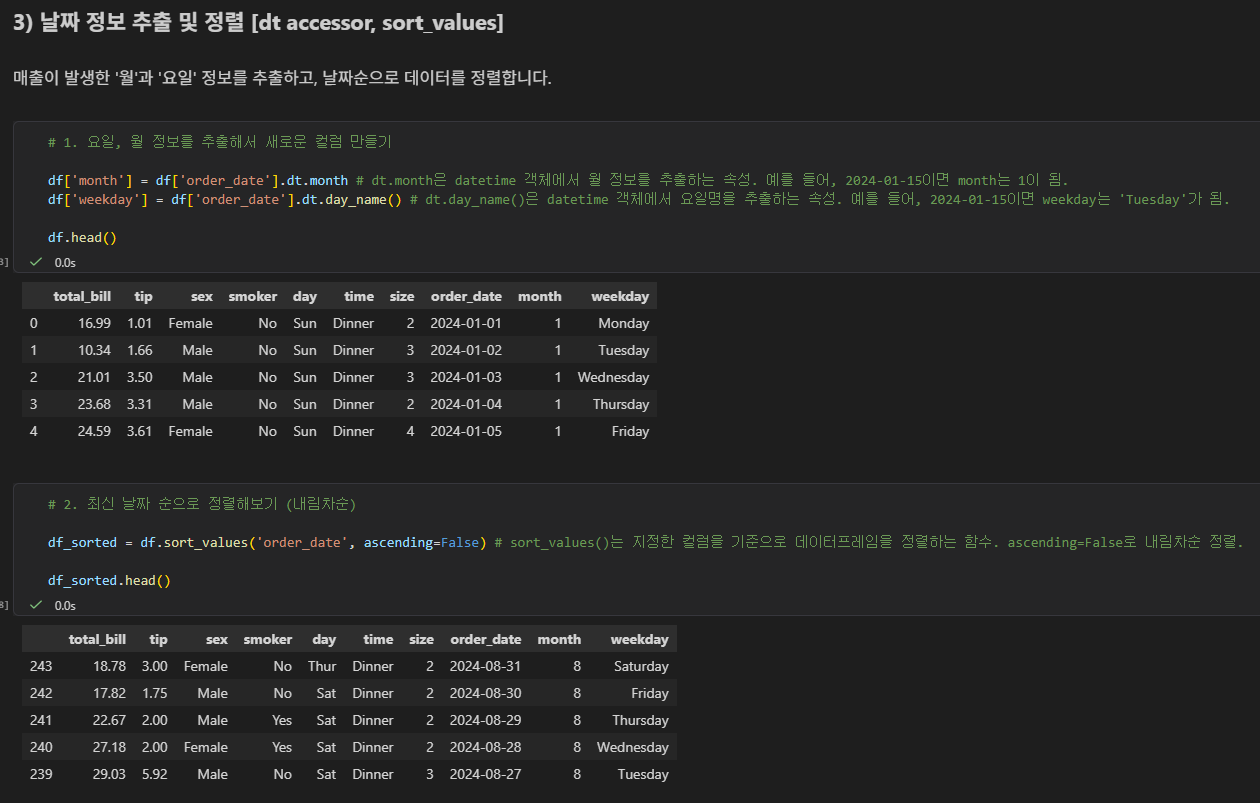




🤔 최대한 라이브 세션에서 다뤘던 함수와 코드를 참고해서 작성했다. 7)그룹 집계(groupby)에서 total_bill 과 tip을 먼저 리스트 형태로 묶어서 계산을 적용하고나서 agg를 사용해서 total_bill의 평균과 tip의 최대값을 계산하는 코드를 짜도 원하는 테이블이 출력이 안되서 GPT의 도움을 살짝 받았다.